Matthew Colón (mcolon21@stanford.edu)
The 2020 NFL Draft has finally arrived. Three jam-packed days full of excitement and new opportunities as we watch the top collegiate talent ascend into the professional ranks of the National Football League. Within the NFL front offices, however, there is a different tone: pressure to make the right choices, and a whole lot of uncertainty. Sure, years of college tape and the NFL Combine should, in theory, provide teams with sufficient information to make the right draft choices, but when you consider the fact that Tom Brady was drafted in the sixth round of the 2000 NFL Draft, and the Chicago Bears passed up on both Patrick Mahomes and DeShaun Watson to draft Mitch Trubisky in 2017, it becomes clear that drafting is still just as much an art as it is a science.
But how skillful are teams at drafting players? Well, it is likely that some general managers and coaches have a more keen eye for true talent than others, but that is not the focus of this analysis. Instead, I am interested in positional discrepancies. Is the league as a whole better at scouting, and thus drafting, talent at certain positions than others at different points of the draft? If this question is answered, it could go a long way toward optimizing drafting strategy by position for teams.
Data
For this analysis, I have used draft data and statistics from Pro Football Reference. More specifically, I have used draft data from thirty-three NFL Drafts (1967-1999), resulting in 11,078 drafted NFL players. More recent NFL Draft data was omitted due to the fact that the career value of players who are still active in the league cannot be accurately calculated until their retirement, yet omitting them completely while including others from their draft classes who have since retired would skew the dataset. Thus, 1999 was chosen as the most recent draft to use in the analysis due to the fact that it is the most recent draft from which all drafted players are now retired (Tom Brady, the oldest current drafted NFL player, was drafted in the 2000 NFL Draft).
Variable of Interest
The variable of interest that I have used for this analysis is Career Weighted Approximated Value, which has also been provided by Pro Football Reference. This statistic is a weighted sum of the Season Approximated Value statistics for a given player. The Season Approximated Value statistic puts a value on a player’s season based on a combination of player achievements and the divvying up of team achievements. For more information on this statistic, check out: https://www.sports-reference.com/blog/approximate-value-methodology/.
Specific Focus: What History Says about Drafting in the Second Round
The first round of the NFL draft came to a close last night. From looking at the Big Boards of experts, it appears as though plenty of talent remains at three key positions which are projected to be heavily drafted in tonight’s second round. Those positions are Running Back, Wide Receiver, and Defensive Back.
While Clyde Edwards-Helaire (LSU) was drafted at the end of the first round by the Kansas City Chiefs, he was the only Running Back off of the board in round one, which few experts had anticipated. Plenty of talent remains that could go a long way toward juicing up NFL backfields, including DeAndre Swift (Georgia), J.K. Dobbins (Ohio State), Jonathan Taylor (Wisconsin), Cam Akers (Florida State), Zack Moss (Utah), among others.
Conversely, six Wide Receivers were taken in the first round, but many analysts have called this Wide Receiver draft class the deepest ever, or at least the deepest since the 2014 class, which included the likes of Mike Evans, Odell Beckham Jr., Davante Adams, Brandon Cooks, and Allen Robinson. That means that there will be plenty of high-quality wideouts still available for Round 2, including Tee Higgins (Clemson), Laviska Shenault Jr. (Colorado), Michael Pittman Jr. (USC), Denzel Mims (Baylor), and K.J. Hamler (Penn State), among others.
As for defensive backs, while the top tier cornerbacks have already been selected, many safeties and other top-tier cornerbacks have fallen much further than anticipated, meaning Round 2 could provide many teams with an opportunity to strengthen their secondary. Safeties such as Xavier McKinney (Alabama), Grant Delpit (LSU), Antoine Winfield Jr. (Minnesota), and Ashtyn Davis (California) were all seen by many as first round talents who have slid outside of the first 32 picks, and cornerbacks such as Kristian Fulton (LSU), Trevon Diggs (Alabama), Jaylon Johnson (Utah), and Bryce Hall (Virginia) are all expected to hear their names called by the commissioner sooner rather than later.
With a high supply of talent at these three positions headed into the second round of the 2020 NFL Draft tonight, my question is this: if I represent a team that needs talent at all three of these positions, or if I represent a team looking for the best value of these three heavy-supply positions, which position should I select in Round 2?
Methodology
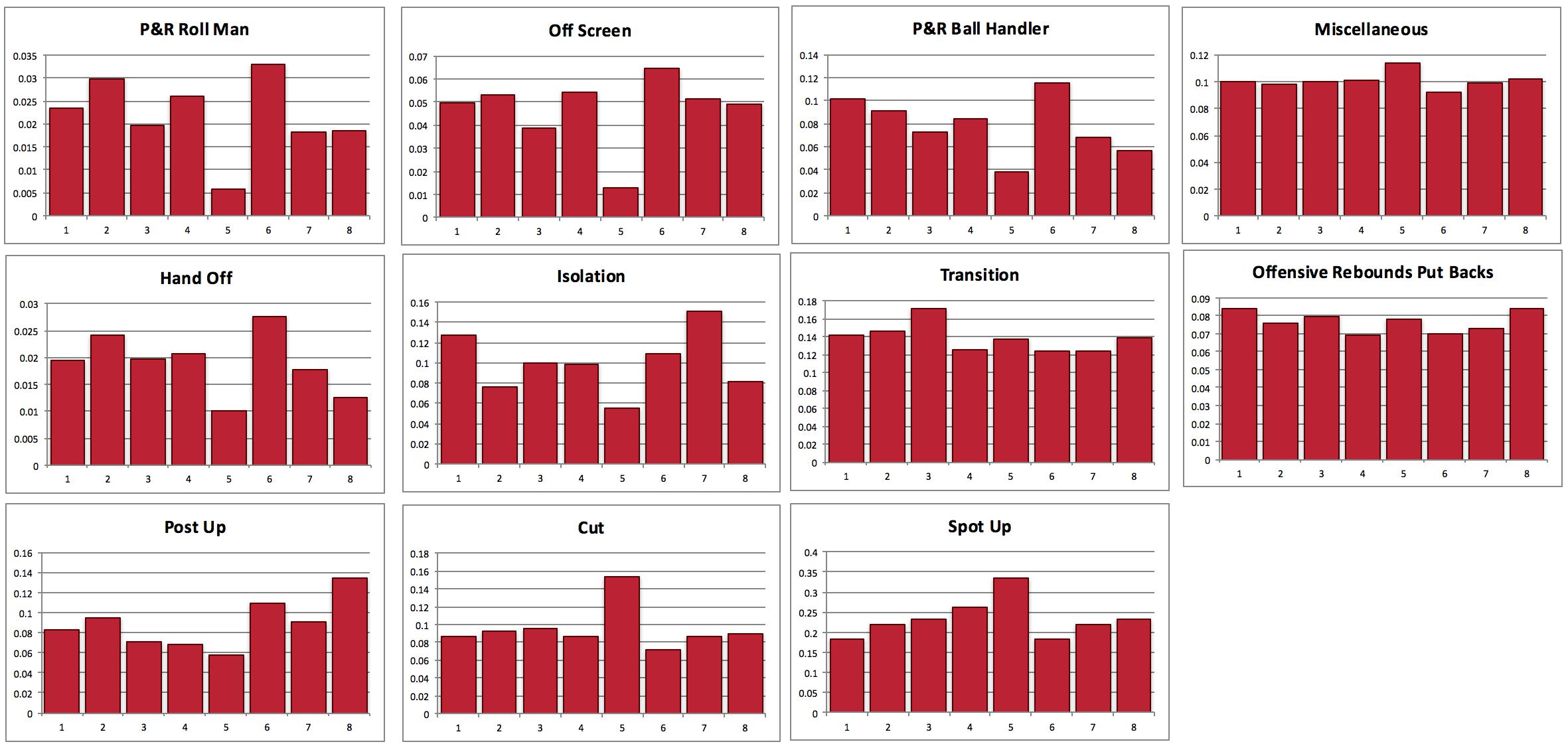
As I mentioned above, I am working with 33 NFL Drafts-worth of data. I broke down this data into eleven positional groups, those being: Quarterback, Running Back, Wide Receiver, Tight End, Center, Tackle, Guard, Defensive End, Defensive Tackle, Linebacker, Defensive Back. I consolidated positions where necessary (such as “Half Backs” and “Running Backs” both being referred to as “Running Backs”). Note that while this analysis is possible with all positional groups, I will solely focus on the positions of Running Back, Wide Receiver, and Defensive Back for the sake of this analysis.
Next, for each position group, I standardized the Career Approximated Value data for each player of that position group. For example, each Running Back was assigned a Career Approximated Value z-score based on the mean and standard deviation statistics of the Running Back distribution. The reason for standardizing the data is that I was worried that the Career Approximated Value statistic may unfairly weight specific positions over others. Since I am solely concerned about drafting the best player in terms of value, I wanted to put all positions on equal footing, and by standardizing by position, I was able to accomplish this.
After that, I focused in on just the players drafted in the “second round” at each of these positions. The reason why “second round” is in quotations is that due to the league expanding significantly since 1967, I did not actually look at solely second round picks. Instead, I looked at picks 33-64 in each draft, corresponding to what in today’s NFL would be the second round. After narrowing down to just the second round, my dataset contained 174 Defensive Backs, 131 Running Backs, and 121 Wide Receivers, which I deemed sufficient in sample size.
Next, looking at the distributions of players drafted in the “second round” at Defensive Back, Running Back, and Wide Receiver, I wanted to know whether or not the distribution of these three positions differed significantly. Here is a box plot of the positional z-score distributions:

A box plot is great, but it’s hard to tell if there is, in actuality, a significant difference between the position groups. While a t-test or an ANOVA test would do the trick in conditions of normally-distributed data, the issue here is that for most position groups, the data is heavily right-skewed, with few players with very high value, and many players with low value. To account for this, I decided to use the Kruskal-Wallis Rank Sum Test, which is a non-parametric method for testing whether samples originate from the same distribution. The key with this method is that it is non-parametric, meaning it does not assume a normal distribution of data.
When we run the Kruskal-Wallis Rank Sum Test, we find the following:

With a p-value of 0.01196, we are confident that we are able to reject the null hypothesis of these distributions originating from the same distribution and conclude that they are distinct distributions. Using the eye test of the box plot, we can see that the rating of these positions from highest to lowest Career Approximated Value appears to be:
- Defensive Back
- Running Back
- Wide Receiver
However, with a test comparing three distributions, it’s hard to know which distributions significantly differ from the others. Thus, let’s conduct this Kruskal-Wallis Rank Sum Test over all pairs.
First, between Defensive Backs and Running Backs:

The p-value of this test is 0.05251. From this, we can reasonably conclude a difference in the distributions between Defensive Backs and Running Backs if we were to use a more lenient 0.10 significance-level threshold, but aren’t completely confident, as the p-value falls almost directly on the commonly-used 0.05 threshold.
Second, let’s compare Defensive Backs and Wide Receivers:

The p-value of this test is 0.00597. From this, we can say with much confidence that the distributions between Defensive Backs and Wide Receivers differ significantly. More specifically, the median Round 2 Defensive Back value is significantly greater than the median Round 2 Wide Receiver value.
Third, let’s compare Running Backs and Wide Receivers:

The p-value of this test is 0.1994. From this, we conclude that there is no difference between the distributions of Running Backs and Wide Receivers.
Historical NFL Draft Analysis: Looking Ahead to Round 2
Takeaways
After observing the box plot and completing multiple Kruskal-Wallis Rank Sum Tests, it can be concluded that Defensive Backs drafted in the second round of the NFL Draft have a higher Career Approximated Value than do Running Backs and Wide Receivers to a significant degree. Thus, if I represent a team that needs talent at all three of these positions, or if I represent a team looking for the highest player value, which is likely the case for several teams headed into the second round of the draft tonight, the best bet according to historical data appears to be to draft a Defensive Back.
In terms of a more broad takeaway, it appears as though teams are more effective at scouting Defensive Backs who are drafted in the second round than they are at scouting Running Backs or Wide Receivers. If this is the case, it makes sense to wait on drafting Running Backs and Wide Receivers if it is known that the scouting of Defensive Backs in the second round can be more heavily relied upon in terms of resulting in a quality player joining the team. Conversely, it is also possible that teams are not very skilled at scouting Defensive Backs in general, allowing highly skilled first-round-talent Defensive Backs to fall to Round 2. If this is the case, it makes sense to scoop up the top tier Defensive Backs in Round 2 that may have been mistakenly overlooked in Round 1.
Moving Forward
I believe that draft strategy remains a confusing art in the NFL today, and analyses like these could go a long way to analyzing what makes for an optimal drafting strategy. I hope to push forward with this analysis using data from other positions and other rounds with the hope of uncovering more significant trends that could help to inform draft strategy moving forward.